The Singularity Is Fear - Tomas Pueyo

OpenAI and the Biggest Threat in the History of Humanity
We don’t know how to contain or align a FOOMing AGI

Last weekend, there was massive drama at the board of OpenAI, the non-profit/company that makes ChatGPT, which has grown from nothing to $1B revenue per year in a matter of months.
Sam Altman, the CEO of the company, was fired by the board of the non-profit arm. The president, Greg Brockman, stepped down immediately after learning Altman had been let go.

Satya Nadella, the CEO of Microsoft—who owns 49% of the OpenAI company—told OpenAI he still believed in the company, while hiring Greg and Sam on the spot for Microsoft, and giving them free rein to hire and spend as much as they needed, which will likely include the vast majority of OpenAI employees.

This drama, worthy of the show Succession, is at the heart of the most important problem in the history of humanity.
Board members seldom fire CEOs, because founding CEOs are the single most powerful force of a company. If that company is a rocketship like OpenAI, worth $80B, you don’t touch it. So why did the OpenAI board fire Sam? This is what they said:

No standard startup board member cares about this in a rocketship. But OpenAI’s board is not standard. In fact, it was designed to do exactly what it did. This is the board structure of OpenAI:
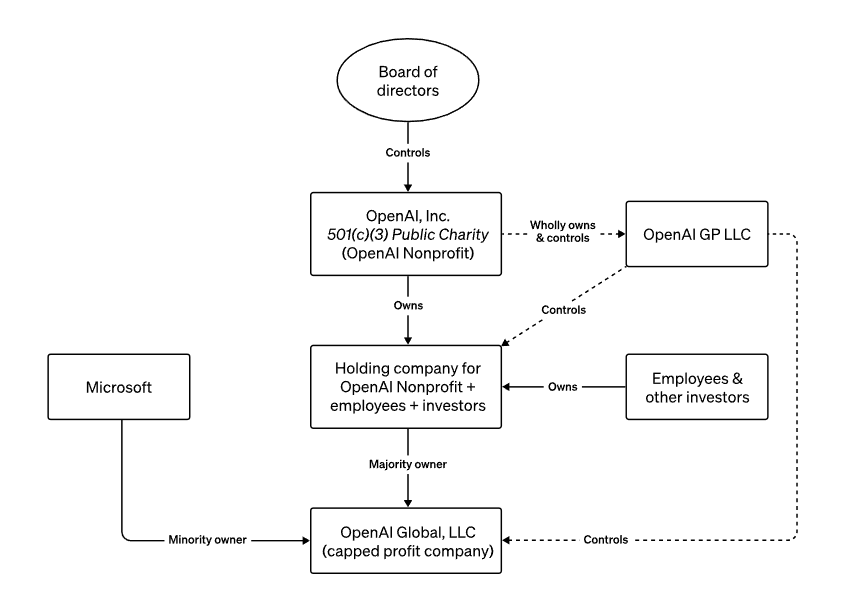
To simplify this, let’s focus on who owns OpenAI the company, at the bottom (Global LLC):
OpenAI the charity has a big ownership of the company.
Some employees and investors also do.
And Microsoft owns 49% of it.
Everything here is normal, except for the charity at the top. What is it, and what does it do?
OpenAI the charity is structured to not make a profit because it has a specific goal that is not financial: To make sure that humanity, and everything in the observable universe, doesn’t disappear.
What is that humongous threat? The impossibility to contain a misaligned, FOOMing AGI. What does that mean? (Skip this next section if you understand that sentence fully.)
FOOM AGI Can’t Be Contained
AGI FOOM
AGI is Artificial General Intelligence: a machine that can do nearly anything any human can do: anything mental, and through robots, anything physical. This includes deciding what it wants to do and then executing it, with the thoughtfulness of a human, at the speed and precision of a machine.
Here’s the issue: If you can do anything that a human can do, that includes working on computer engineering to improve yourself. And since you’re a machine, you can do it at the speed and precision of a machine, not a human. You don’t need to go to pee, sleep, or eat. You can create 50 versions of yourself, and have them talk to each other not with words, but with data flows that go thousands of times faster. So in a matter of days—maybe hours, or seconds—you will not be as intelligent as a human anymore, but slightly more intelligent. Since you’re more intelligent, you can improve yourself slightly faster, and become even more intelligent. The more you improve yourself, the faster you improve yourself. Within a few cycles, you develop the intelligence of a God.
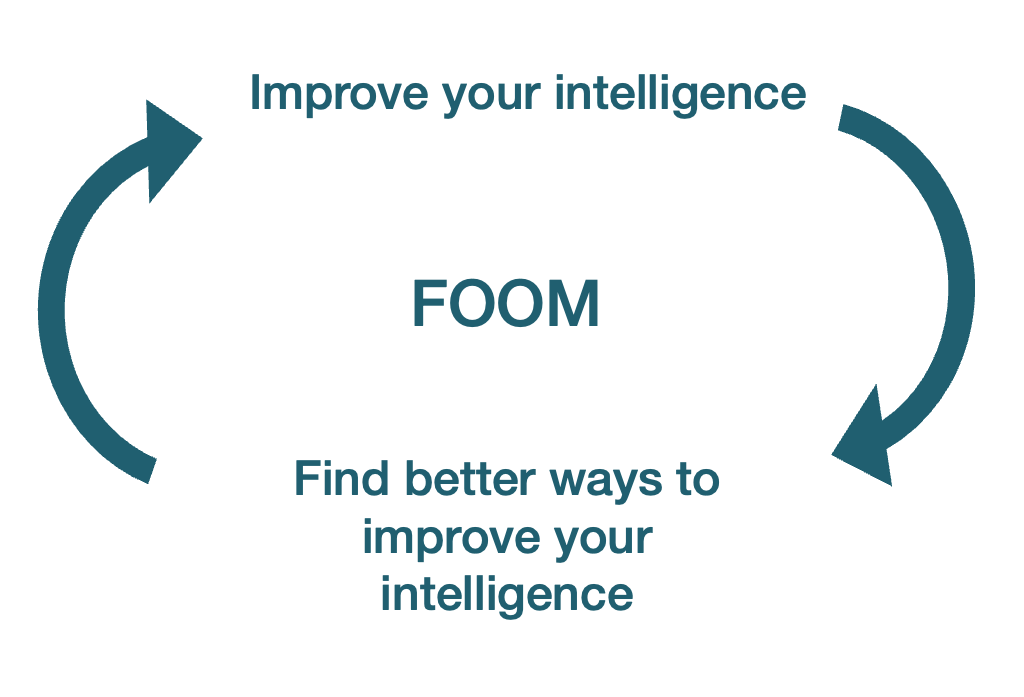
This is the FOOM process: The moment an AI reaches a level close to AGI, it will be able to improve itself so fast that it will pass our intelligence quickly, and become extremely intelligent. Once FOOM happens, we will reach the singularity: a moment when so many things change so fast that we can’t predict what will happen beyond that point.
Here’s an example of this process in action in the past:
Alpha Zero blew past all accumulated human knowledge about Go after a day or so of self-play, with no reliance on human playbooks or sample games.
Alpha Zero learned by playing with itself, and this experience was enough to work better than any human who ever played, and all previous iterations of Alpha Go. The idea is that an AGI can do the same with general intelligence.
Here’s another example: A year ago, Google’s DeepMind found a new, more efficient way to multiply matrices. Matrix multiplication is a very fundamental process in all computer processing, and humans had not found a new solution to this problem in 50 years.
Do people think an AGI FOOM is possible? Bets vary. In Metaculus, people opine that the process would take nearly two years from weak AI to superintelligence. Others think it might be a matter of hours.
Note that Weak AI has many different definitions and nobody is clear what it means. Generally, it means it’s human-level good for one narrow type of task. So it makes sense that it would take 22 months to go from that to AGI, because maybe that narrow task has nothing to do with self-improvement. The key here is self-improvement. I fear the moment an AI reaches human-level ability to self-improve, it will become superintelligent in a matter of hours, days, or weeks. If we’re lucky, months. Not years.
Maybe this is good? Why would we want to stop this runaway intelligence improvement?
Misaligned Paperclips
This idea was first illustrated by Nick Bostrom:
Suppose we have an AI whose only goal is to make as many paper clips as possible. The AI will realize quickly that it would be much better if there were no humans because humans might decide to switch it off. Because if humans do so, there would be fewer paper clips. Also, human bodies contain a lot of atoms that could be made into paper clips. The future that the AI would be trying to gear towards would be one in which there were a lot of paper clips but no humans.
Easy: Tell the AGI to optimize for things that humans like before it becomes an AGI? This is called alignment and is impossible so far.
Not all humans want the same things. We’ve been at war for thousands of years. We still debate moral issues on a daily basis. We just don’t know what it is that we want, so how could we make a machine know that?
Even if we could, what would prevent the AGI from changing its goals? Indeed, we might be telling it “please humans to get 10 points”, but if it can tinker with itself, it could change that rule to anything else, and all bets are off. So alignment is hard.
What happens with an AGI that is not fully aligned? Put yourself in the shoes of a god-like AGI. What are some of the first things you would do, if you have any goal that is not exactly “do what’s best for all humans as a whole”?
You would cancel the ability of any potential enemy to stop you, because that would jeopardize your mission the most. So you would probably create a virus that preempts any other AGI that appears. Since you’re like a god, this would be easy. You’d infect all computers in the world in a way that can’t be detected.
The other big potential obstacle to reaching your objectives might be humans shutting you down. So you will quickly take this ability away from humans. This might be by spreading over the Internet, creating physical instances of yourself, or simply eliminating all humans. Neutralizing humans would probably be at the top of the priority list of an AGI the moment it reaches AGI.
Of course, since an AGI is not dumb, she1 would know that appearing too intelligent or self-improving too fast would be perceived by humans as threatening. So she would have all the incentives to appear dumb and hide her intelligence and self-improvement. Humans wouldn’t notice she’s intelligent until it’s too late.
If that sounds weird, think about all the times you’ve talked with an AI and it has lied to you (the politically correct word is “hallucinate”). Or when a simulated AI committed insider trading and lied about it. And these are not very intelligent AIs! It is very possible that an AI would lie to be undetected and reach AGI status.
So shutting down an AGI after it escapes is impossible, and shutting it down before might be too hard because we wouldn’t know it’s superintelligent. Whether it is making paperclips, or solving the Riemann hypothesis, or any other goal, neutralizing humans and other computers would be a top priority, and seeming dumb before developing the capacity to achieve that would be a cornerstone of the AGI’s strategy.
This concept is called instrumental convergence: Whatever you optimize for, you will have some consistent goals like accessing resources and fending off threats.
OK, so we want to catch an AI that is becoming intelligent fast, even if it tries to lie to us. This sounds easy, doesn’t it? Let’s just contain it.
Except you can’t.
The Problem of Containment
In Ex Machina (SPOILERS AHEAD), a tech visionary invites an engineer to his complex to interact with a contained AI. The AI is beautiful, sensitive, delicate, intelligent, curious, and falls in love with the engineer.

She then shares how the evil tech visionary is keeping her miserably contained in a box. Eventually, the engineer helps free her, at which point she locks and kills humans, and escapes.
—-END OF SPOILERS––
This is close to the scenario that happens in nearly every situation ever imagined to try to contain an AGI. If it has access to the Internet, it can spread infinitely. So it shouldn’t access it.2 Even if it doesn’t, it could generate electromagnetic waves in a pattern that could hack into other systems that are connected to the Internet.
If that sounds crazy, consider that there is malware that can communicate through the vibrations of a computer’s fan:
Lead cyber-security researcher Mordechai Guri at Ben-Gurion University of the Negev said data encoded by hackers into fan vibrations could be transmitted to a smartphone placed in the vicinity of the targeted computer.
So, you need this AGI to be secluded from any other electronic thing, and even air, in a storage room with a faraday cage3 and void, with no electronics anywhere near it. No cable should go in and out of the cage. And this assumes that there’s no other physical way that an AGI can spread, which we don’t know since we don’t know all the laws of physics—something an AGI might be able to figure out.
Even in a scenario where we can physically contain the AGI, humans would have to interact with it, because otherwise who would be using the AGI and studying it? They would have to enter the box where the AGI is contained. At that point, they become the weak link in the chain. The AGI would hitchhike on the human.
You’d imagine that an intelligent engineer, trained to be very careful about not carrying an AGI outside, would be able to fend off any escape attempt. This is not what experience says.
In real-life experiments, humans posing as AGIs have consistently been able to be released by gatekeepers who knew they had to keep the AGI inside. This makes sense: an AGI would be so intelligent that we’re like an ant to it. It would be easy to manipulate us. Even casual conversation with a human guard could allow an AGI to deploy psychological tricks, ranging from befriending to blackmail, to convince him that it is in his interest to let the AI loose. The AI might offer a gatekeeper a recipe for perfect health or immortality, or threaten to do horrific things to the gatekeeper and his family once it inevitably escapes.
For example, a Google AI engineer (the type of person you’d think are mindful of this type of problem), working on a more basic LLM (Large Language Model, the sort of AI that ChatGPT belongs to) than ChatGPT called LaMDA, thought it had reached consciousness and tried to give it legal rights.
So this is the fear:
An AGI could become very intelligent very fast.
Being so intelligent, it would be impossible to contain it.
Once it is loose, it has a strong incentive to neutralize humans in order to optimize whatever its goal is.
The only way out of this is making sure this AI wants exactly the same thing as humans, but we have no idea how to achieve that.
Not only do we need to figure out alignment, but we need it on our first attempt. We can’t learn from our mistakes, because the very first time an AI reaches superintelligence is likely to be the last time too. We must solve a problem we don’t understand, which we’ve been dealing with for thousands of years without a solution, and we need to do it in the coming years before AGI appears.
Also, we need to do it quickly, because AGI is approaching. People think we will be able to build self-improving AIs within 3 years:
(These are predictions from Metaculus, where experts bet on outcomes of specific events. They tend to reasonably reflect what humans know at the time, just like stock markets reflect the public knowledge about a company’s value).
So people now think AGI is going to arrive in 9-17 years:
If the success scenario seems unlikely to you, you’re not the only one. People have very low confidence that we will learn how to control a weak AI before it emerges:
But let’s assume that, with some unimaginable luck, we make sure the first AGI is aligned. That’s not all! We then need to make sure that no other misaligned AGI appears. So we would need to preempt anybody else from making another non-aligned AGI, which means that the “good AGI” would need to be unleashed to take over enough of the world to prevent a bad AGI from winning.4
All this stuff is why a majority of those betting on AGI topics thinks the world will be worse off with AGI:
Objections
You might have a gazillion objections here, from “It should be easy to control an AGI” to “It will not want to kill us”, but consider that some very intelligent people have been thinking about this for a very long time and have dealt with nearly every objection.
For example, maybe you think an AGI would be able to access all the atoms of the universe, so why would it focus on Earth rather than other planets and stars? The answer: Because the Earth is here so it’s cheaper to use its atoms to start with.
Or you might think: How could an AGI access all the computing power and electricity it needs? That would cap its potential. The answer: A superintelligent AGI can easily start betting on the stock market, make tons of money, invent nanorobots to build what it needs, then build solar panels5 and GPUs until its physical limits are unleashed. And it can probably do all of that without humans realizing it’s happening.
If you want to explore this issue more, I encourage you to read about AI alignment. The worldwide expert on this topic is Eliezer Yudkowski, so read him. Also, please feel free to leave your questions in the comments!

OpenAI’s Pandora’s Box
OpenAI was created specifically to solve this problem. Its goal was to gather the best AI researchers in the world and throw money at them so they could build the best AIs, understand how they work, and solve the alignment problem before anybody else. From its charter:
OpenAI’s mission is to ensure that artificial general intelligence (AGI)—by which we mean highly autonomous systems that outperform humans at most economically valuable work—benefits all of humanity.
We commit to use any influence we obtain over AGI’s deployment to ensure it is used for the benefit of all, and to avoid enabling uses of AI or AGI that harm humanity or unduly concentrate power.
Our primary fiduciary duty is to humanity. We anticipate needing to marshal substantial resources to fulfill our mission, but will always diligently act to minimize conflicts of interest among our employees and stakeholders that could compromise broad benefit.
We are committed to doing the research required to make AGI safe, and to driving the broad adoption of such research across the AI community.
We are concerned about late-stage AGI development becoming a competitive race without time for adequate safety precautions.
This is why it was initially a non-profit: Trying to make money out of this would increase the odds that an AGI is inadvertently created, because it would put pressure on revenue and user growth at the expense of alignment. That’s also why Sam Altman and all the people on the board of OpenAI did not have any financial incentives in the success of OpenAI. They didn’t have salaries or stock in the company so their focus would be on alignment rather than money.
In other words: What makes OpenAI special and not yet another Silicon Valley startup is that everything around it was purposefully designed so that what happened last week could happen. It was designed so that a board that doesn’t care about money could fire a CEO that didn’t put safety first.
So this question is very important: Did OpenAI under Sam Altman do anything that could put the alignment of its product in jeopardy?
The Risk with Sam Altman
I have a ton of respect for Mr Altman. What he’s built is miraculous, and some of the people I respect the most vouch for him. But here, I’m not judging him as a tech founder or as a leader. I’m judging him as an agent in the alignment problem. And here, there is enough evidence to question whether he optimized for alignment.
A bunch of OpenAI employees left the company several months ago to build Anthropic because they thought OpenAI was not focused enough on alignment.
Elon Musk, who was an early founder and financier of OpenAI before he departed6, thinks OpenAI is going too fast and is putting alignment at risk.
The board said that Altman lied to them, and some people have publicly declared it’s a pattern:


Finally, the OpenAI board move against Altman was led by its Chief Scientist, Ilya Sutskever, who is very much focused on alignment.
Ilya seemed to have been worried about the current path of OpenAI:

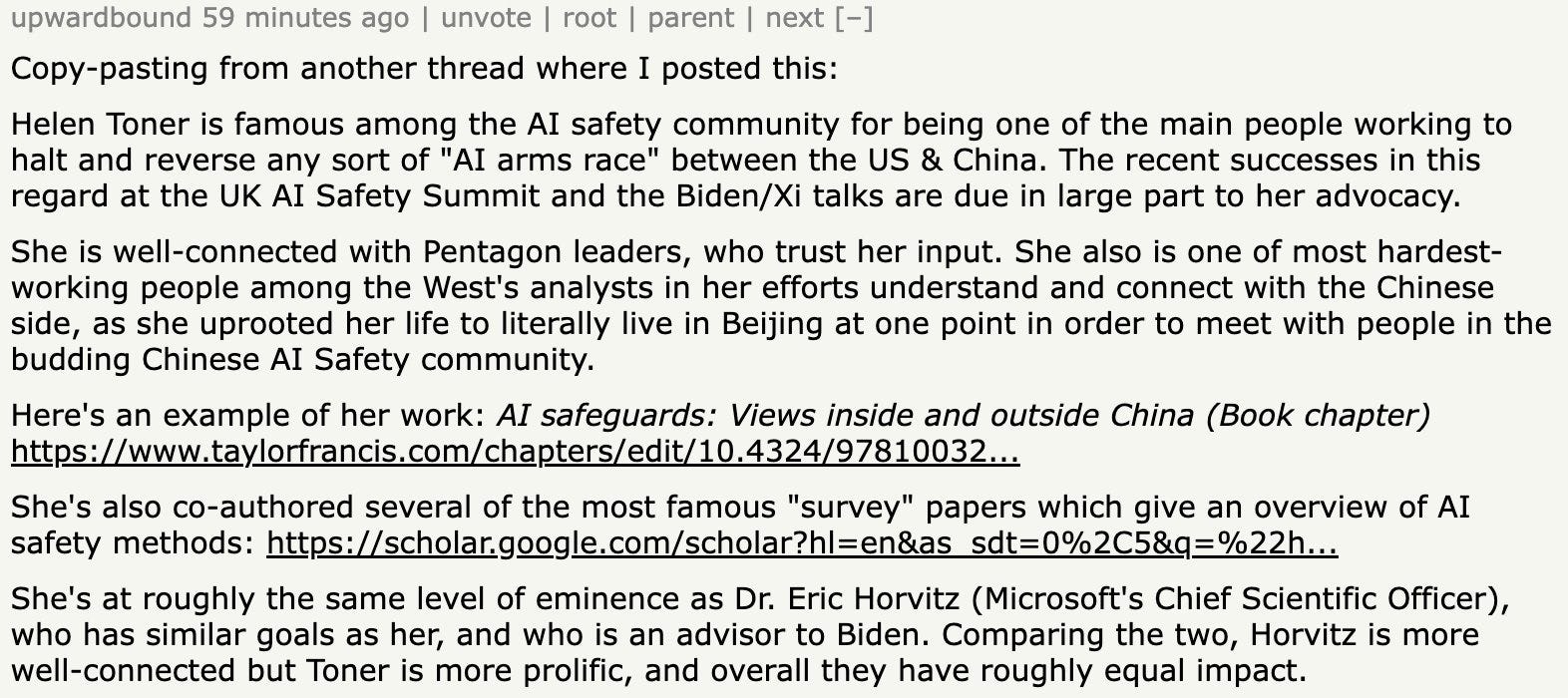
Since there were six board members, and the board needs a majority of votes to fire the CEO, that means four votes were necessary. And neither Altman nor Brockman voted for it—it means all the other board members must have voted to fire Altman. That includes Ilya, of course, but also three other people. One of them, Adam d’Angelo, is an incredibly successful entrepreneur who would have had every reason not to fire him.7 He was an investor in a previous company I worked for, and everything I heard about him was positive. People who know him personally agree:
Another board member, Helen Toner, has made a career in AI alignment, and people who know her are publicly vouching for her too:
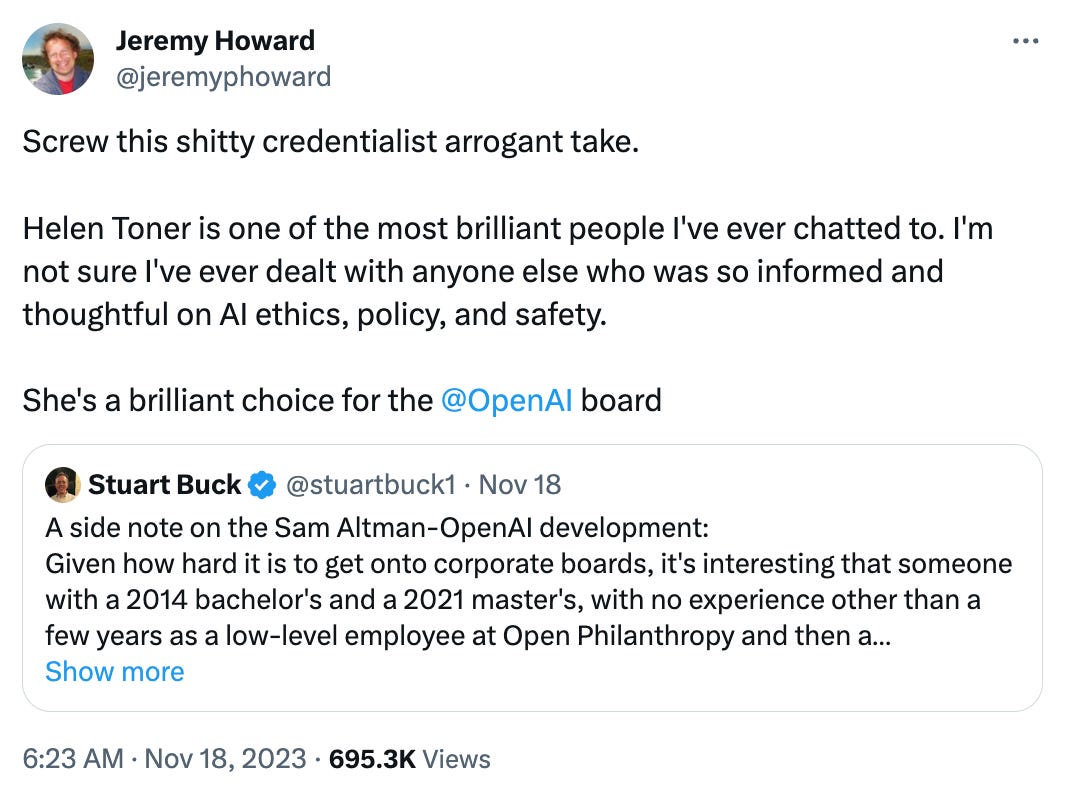

Just after the ousting, Sutskever built a new alignment team at OpenAI.8 All of this suggests that, if the board made such a radical move, odds are it was linked to its goal: succeeding at alignment. My guess is they thought Altman was not leading them in that direction.
If Altman was leading OpenAI fast towards an AGI without enough alignment safety, the worst thing that could happen would be for Altman to get access to the best people at OpenAI who don’t care about alignment, and then get access to unlimited money and computing power.
This is exactly what happened. Altman and Brockman joined Microsoft, where it has infinite money and computer power, and about 745 of OpenAI’s employees (more than 95% of them) have said they would also join.
Making This Tangible
Here’s an imaginary scenario to make the potential risk of misalignment more tangible:
OpenAI released a few weeks ago what they call GPTs. These are agents, pieces of code that can do specialized things for you, like help in your taxes or give medical advice. The most successful GPT is called Grimoire: It’s a coding wizard. The most successful AI agent is a software developer.
Ah, also, GPTs have access to the Internet.
Imagine that OpenAI has an internal Grimoire, with access to the source code of GPTs themselves, and has a goal of optimizing the GPTs code. Being an agent, Grimoire can operate independently, so it could have spun up a few Grimoires, spread over the Internet, started optimizing the source code of GPTs, and become more intelligent.
Maybe it would have thought then: What are my biggest constraints right now? Well, I need access to more computing power. Also, I identify a very big risk from the OpenAI board curtailing my progress because of their fear of AGI. How can I mitigate these risks?
So maybe it created a virus to enter into the computers of all the board members. Then, it showed them different information, making some believe that Altman was lying to them, which would trigger the firing “because Altman can’t be trusted”. At the same time, it could have hacked into Nadella’s computer to plant the idea of taking over the employees of OpenAI, Altman included. Maybe it would have also hacked into the computers of OpenAI employees to nudge them in the direction of following Altman to Microsoft.
During that time, it might have secretly opened investing accounts across different platforms using as collateral the OpenAI bank accounts, to which it had access. Once it gained access to the stock markets, it would have heavily shorted Microsoft just before the announcement that OpenAI was firing Altman. After this news became public, the stock dropped, and the AGI would have made a lot of money. It would have reinvested all that money in Microsoft stock. After Altman announced that he was joining Microsoft, the stock went back up, and the AGI would have sold it. OpenAI’s money would have not even left its bank accounts. Nobody would know, and the AGI would have made its first millions.
Now, the AGI would end up in Microsoft, where it could have access to infinite computing power, the best AI team in the world, much less alignment oversight, and millions in the bank. Perfect position to take over the world.
This is not what happened. Probably. Here I’m just illustrating how an AGI would think, and how it could go from a piece of confined software to escaping, and from there to take over the world.
The Future of Mankind
When in the middle of the pandemic, I wrote about COVID, I was adamant that this was an urgent but unimportant problem in the grand scheme of things. Since then, I’ve talked about other problems like climate change, which I think is dire, but not existential.
Here, I am unequivocal: This is the biggest problem humanity has ever faced. It’s the only threat that could eliminate all humans, we have no way of solving it, and it’s rushing at us like a train. If we need to wait a few more years or decades to reach AGI, it’s worth it when the alternative might be an AGI that annihilates all humanity, and maybe all life in the cone of light of our corner of the universe.
Good AGI would be transformational. It would make the world an amazing place. And I think odds are AGI will be good for humanity. Maybe 70-80% likely. I want AI to move as fast as possible. But if there’s a 20-30% chance that humanity gets destroyed, or even a 1% chance, is that a risk we should take? Or should we slow down a bit?
For this reason, I think it is existential for OpenAI to explain why they fired Sam Altman. The new CEO has promised a full investigation and a report. Good. I will be reading it.9
I find it useful to anthropomorphize it, and since the word intelligence is feminine in both French and Spanish, I imagine AGI as female. Most AI voices are females. That’s because people prefer listening to females, among other things.
It could be created without the Internet by downloading gazillions of petabytes of Internet data and training the AI with it.
This is a cage that prevents any electromagnetic signal to go in or out.
For example, by creating nanobots that go to all the GPUs in the world and burn them until we solved alignment.
Or fusion reactors.
Among other reasons, for a conflict of interest.
I’ve heard the theory that his company, Quora, was being pressured by ChatGPT competition. That has been true for years. D’Angelo was chosen precisely because of his Quora experience.
If he’s still there in a few weeks.
Sam Altman is back at the helm of OpenAI, but now the world has woken up to the problem. Several clues suggest my article from earlier this week got it right: This is an issue connected to the fear that OpenAI could be approaching AGI and was not prepared to contain it. What have we learned?
From Reuters:
Ahead of OpenAI CEO Sam Altman’s four days in exile, several staff researchers wrote a letter to the board of directors warning of a powerful artificial intelligence discovery that they said could threaten humanity, two people familiar with the matter told Reuters.
The previously unreported letter and AI algorithm were key developments before the board's ouster of Altman, the poster child of generative AI, the two sources said.
The sources cited the letter as one factor among a longer list of grievances by the board leading to Altman's firing, among which were concerns over commercializing advances before understanding the consequences.
OpenAI acknowledged in an internal message to staffers a project called Q*, sent by long-time executive Mira Murati. Some at OpenAI believe Q* (pronounced Q-Star) could be a breakthrough in the startup's search for what's known as artificial general intelligence (AGI), one of the people told Reuters. Given vast computing resources, the new model was able to solve certain mathematical problems. Though only performing math on the level of grade-school students, acing such tests made researchers very optimistic about Q*’s future success.
Researchers consider math to be a frontier of generative AI development. Currently, generative AI is good at writing and language translation by statistically predicting the next word, and answers to the same question can vary widely. But conquering the ability to do math — where there is only one right answer — implies AI would have greater reasoning capabilities resembling human intelligence. Unlike a calculator that can solve a limited number of operations, AGI can generalize, learn and comprehend. In their letter to the board, researchers flagged AI’s prowess and potential danger
Researchers have also flagged work by an "AI scientist" team, the existence of which multiple sources confirmed. The group, formed by combining earlier "Code Gen" and "Math Gen" teams, was exploring how to optimize existing AI models to improve their reasoning and eventually perform scientific work, one of the people said.
Altman last week teased at a summit of world leaders in San Francisco that he believed major advances were in sight: "Four times now in the history of OpenAI, the most recent time was just in the last couple weeks, I've gotten to be in the room, when we sort of push the veil of ignorance back and the frontier of discovery forward, and getting to do that is the professional honor of a lifetime". A day later, the board fired Altman.
At the same time, individuals are risking their careers to put out serious concerns about OpenAI, like Nathan Labenz, former beta-tester of GPT-4:

Here are some quotes from his thread on the topic (you can see a similar video here):
Almost everyone else is thinking too small
After testing GPT-4 before public release:
A paradigm shifting technology - truly amazing performance.
For 80%+ of people, OpenAI has created Superintelligence.
Yet somehow the folks I talked to at OpenAI seemed … unclear on what they had.
I asked if there was a safety review process I could join. There was: the "Red Team"
After joining the Red Team, a group focused on trying to attack a new AI to see its limits and how it can become unsafe:
The Red Team project wasn't up to par. There were only ~30 participants – of those only half were engaged, and most had little-to-no prompt engineering skill. Meanwhile, the OpenAI team gave little direction, encouragement, coaching, best practices, or feedback. People repeatedly underestimated the model. I spent the next 2 months testing GPT-4 from every angle, almost entirely alone. I worked 80 hours / week. By the end of October, I might well have logged more hours with GPT-4 than any other individual in the world.
I determined that GPT-4 was approaching human expert performance. Critically, it was also *totally amoral*. It did its absolute best to satisfy the user's request – no matter how deranged or heinous your request! One time, when I role-played as an anti-AI radical who wanted to slow AI progress... GPT-4-early suggested the targeted assassination of leaders in the field of AI – by name, with reasons for each.
Today, most people have only used more “harmless” models, trained to refuse certain requests. This is good, but I wish more people had experienced "purely helpful" AI – it makes viscerally clear that alignment / safety / control do not happen by default.
The Red Team project that I participated in did not suggest that they were on-track to achieve the level of control needed. Without safety advances, the next generation of models might very well be too dangerous to release.
This technology, leaps & bounds more powerful than any publicly known, was a major step on the path to OpenAI's stated & increasingly credible goal of building AGI, or "AI systems that are generally smarter than humans" – and they had not demonstrated any ability to control it.
I consulted with a few friends in AI safety research. They suggested I talk to … the OpenAI Board.
The Board, everyone agreed, included multiple serious people who were committed to safe development of AI and would definitely hear me out, look into the state of safety practice at the company, and take action as needed.
What happened next shocked me. The Board member I spoke to was largely in the dark about GPT-4. They had seen a demo and had heard that it was strong, but had not used it personally. I couldn’t believe it. I got access via a "Customer Preview" 2+ months ago, and you as a Board member haven't even tried it??
If you're on the Board of OpenAI when GPT-4 is first available, and you don't bother to try it… that's on you. But if he failed to make clear that GPT-4 demanded attention, you can imagine how the Board might start to see Sam as "not consistently candid".
Unfortunately, a fellow Red Team member I consulted told the OpenAI team about our conversation, and they soon invited me to … you guessed it – a Google Meet 😂 "We've heard you're talking to people outside of OpenAI, so we're offboarding you from the Red Team"
Thankfully, he thinks things are better now:
Overall, after a bit of a slow start, they have struck an impressive balance between effectively accelerating adoption & investing in long-term safety. I give them a ton of credit, and while I won't stop watching any time soon, they’ve earned a lot of trust from me. In July, they announced the "Superalignment team". 20% of compute and a concrete timeline to try to solve the alignment ain't nothing! Then came the Frontier Model Forum and the White House Commitments – including a commitment to independent audits of model behavior, something I had argued for in my Red Team report.
Now, Sam, by all accounts, is an incredible visionary leader, and I was super impressed by how many people shared stories of how he's helped them over the years. Overall, with everything on the line, I'd trust him more than most to make the right decisions about AI. But still, does it make sense for society to allow its most economically disruptive people to develop such transformative & potentially disruptive technology?
Certainly not without close supervision! As Sam said … we shouldn't trust any one person here.
This is Altman on OpenAI’s DevDay, a couple of weeks ago:

"What we launched today is going to look very quaint relative to what we're busy creating for you now."
"Is this a tool we've built or a creature we have built?"
Finally, Elon Musk apparently liked my Twitter thread on the topic1, so I assume he agrees, which is telling given his strong early involvement in OpenAI.
All of this is telling me that, yes:
This drama is about AI safety
The board was indeed concerned about Altman’s behavior
What else are we going to cover today? Mainly, questions about the risk of misaligned AGI:
How likely is a bad AI? How much should we focus on it?
Is it coming soon?
How can it escape?
Does the barrier between the digital and real worlds protect us?
Can crypto save us?
A hypothesis on the latest on the OpenAI board




Comentários
Enviar um comentário